//
//K-nn Segmentation command
//
//This command calc probabrity of segmentation by k nearest neighborhood method.
//(Caution)
//It is necessary to make the segment variable a number except 0 for learning.
//The record with a segment variable of 0 value is predicted.
//Syntax no option
k_nn [variables] by [segmentation variable];
//Syntax used options
k_nn [variables] by [segmentation variable]/
Options
;
//Options
count:nn //nn is number of neighbarbood calculation(default=4).
//
//Example 1
//last 3 record are to be predicated segment by kbn=0.
//
hand x,y,kbn/
0.0193,0.5263,1
0.3862,0.3479,1
0.9032,0.2082,2
0.7364,0.0560,2
0.7019,0.3712,2
0.3042,0.1129,1
0.2949,0.6462,1
0.5419,0.3297,2
0.3826,0.3010,1
0.8027,0.2975,2
0.3, 0.2, 0
0.9, 0.4, 0
0.5, 0.4, 0
;
//save hand in data to temp file .
put wrk;
//View node by plot. So kbn is defined as code for plot;
plot x y by kbn/
kbn:code
;
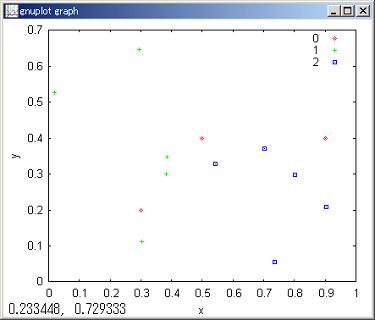
mark ü× are to be predicted segment.
//Execute k-nn analyis which uses 4 neighborhood by option.
k_nn x y by kbn/
count:4
;
//Below is output that shows probablity of segment for nodes that are appointed by kbn=0.
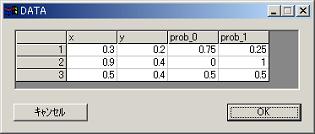
prob_0 is probabilty of belonging to segment 1.
prob_1 is probabilty of belonging to segment 2.
//
//Plot predicted nodes and probabilty.
//
//Get output of k-nn and rename prob_0 to kbn.
get freq@ana;
rename prob_0=kbn;
put out1;
//Delete nodes to be predicted from original data.
get wrk;
if(kbn == 0) {
delrec;
}
//Concatiname predicted nodes.
concat out1;
//Plot predicted nodes and probabilty of prob_0.
plot scat x y by kbn/
kbn=code;
;
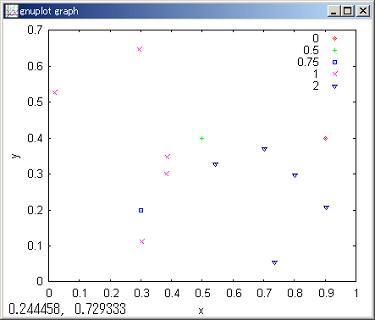
mark ü× is 0% probabirity which belong to segment 1.
mark ü{ is 50% probabilty which belong to segment 1.
mark üĀ is 75% probabilty which belong to segment 1.
//
//Compare segmentation outputs by maharanobis method with same data.
//
get wrk;
maha x y by kbn;
//Below is output of maharanobis analysis.
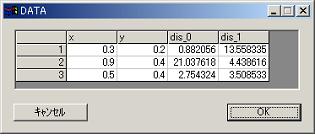
dis_0 is distance from center of segment 1.
dis_1 is distance from center of segment 2.
Minimum distance side belongs to segment.